Inside the Wiki4What Workflow Company
A public teardown of Wiki4What as an agent-run workflow company: constitution, roles, skills, command-line tools, archives, and vector memory.
Chinese version: 中文版
Most people still describe AI workflows as a chain of prompts.
Prompt one writes the draft. Prompt two edits it. Prompt three formats it. Prompt four publishes it. If something breaks, a human steps in, guesses what went wrong, and tries again.
That is not a workflow. That is a conversation with a very talented freelancer who forgets the company handbook every morning.
A real AI workflow needs more than prompts. It needs a constitution, a division of labor, a memory system, a tool floor, a publishing desk, and a way to review its own failures. It needs the boring things that make organizations work: roles, handoffs, checklists, logs, rules, and machines that do not improvise when determinism is available.
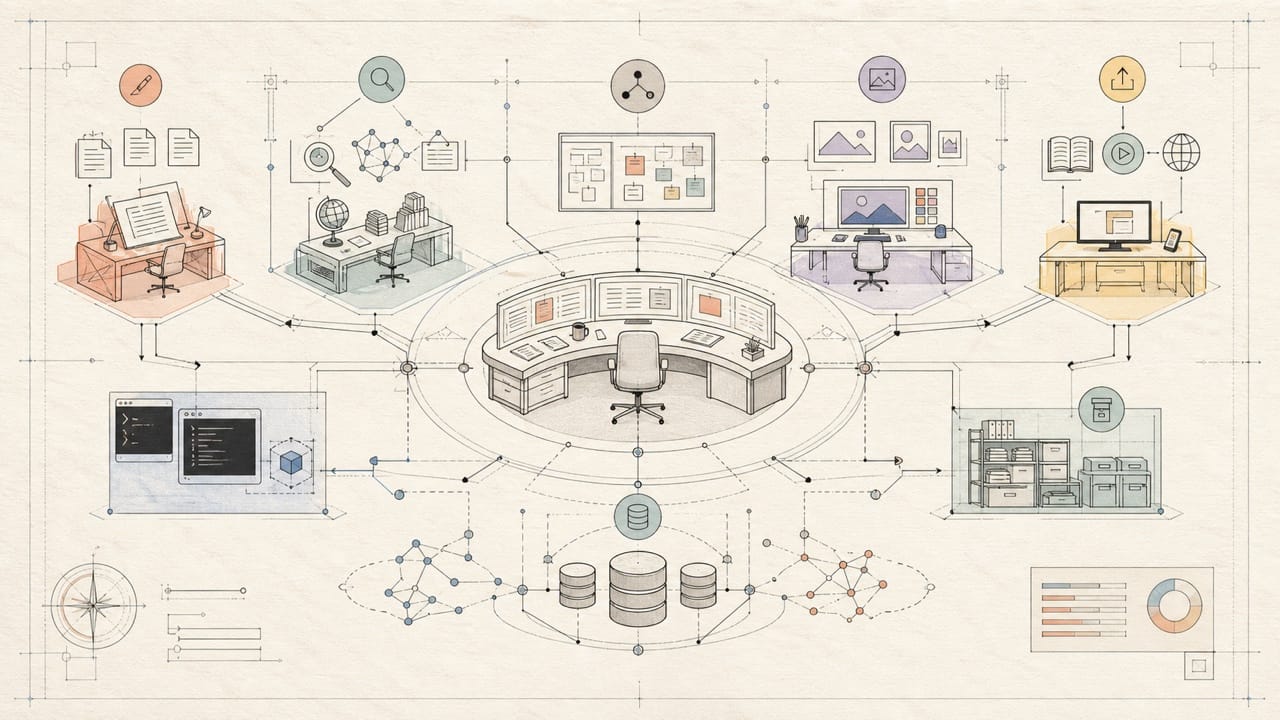
Wiki4What is my public case study for that idea. It is an English YouTube channel and Ghost blog about thinking clearly in the AI era. Behind the public output is an agent-run production company: Claude Code acts as the operating CEO, Codex acts as the external visual studio for still images and code-side collaboration, and a small set of specialized sub-agents handle scripts, research, structure, scenes, publishing, captions, archives, and maintenance.
This essay is a public teardown of that workflow company: what documents it needs, what roles it has, what tools sit underneath, and how one piece of content moves from an idea to a published asset without relying on one giant prompt.
The mental model: a workflow is a company
The most useful shift is to stop asking, “What prompt should I write?” and start asking, “What company am I building?”
A company has laws. It has a CEO. It has departments. It has employees with job descriptions. It has shared manuals. It has machines on the factory floor. It has a filing system. It has a way to check whether work is complete before it ships.
An agent workflow needs the same layers:
| Company layer | Workflow equivalent | Why it matters |
|---|---|---|
| Constitution | CONSTITUTION.md |
Defines the non-negotiables and judgment rules |
| Operating manual | WORKFLOW.md |
Describes the production spine from idea to publication |
| Org chart | ROLES.md |
Assigns responsibility to sub-agents and skills |
| Training manuals | Skills | Teach reusable capabilities without bloating every prompt |
| Factory machines | CLI tools and APIs | Execute deterministic work repeatedly |
| Archive | Content store + vector DB | Preserves final assets for search and reuse |
| Board review | Human approval gates | Keeps subjective judgment with the owner |
If one of these layers is missing, the system starts leaking responsibility into the chat window. The main agent has to remember policies. The worker agents improvise. Publishing becomes a ritual instead of an operation. The same dependency breaks twice. The same article gets created twice because no one searched the archive.
The cure is not a longer prompt. The cure is a better company.
The constitution: law before taste
Every serious workflow needs a constitution: a short, durable document that answers, “What kind of organization are we?”
In the Wiki4What production company, the constitution defines the operating posture:
- The human owner sets direction, approves subjective quality, and decides brand value.
- The main agent is the CEO: it decomposes work, dispatches specialists, audits output, and reports honestly.
- Sub-agents are employees or department heads: they receive bounded jobs and produce verifiable artifacts.
- Repeatable mechanical steps should become command line tools.
- Bugs should improve the system, not merely be patched for one run.
- Sensitive credentials must never be written into ordinary documents or commits.
The point is not bureaucracy for its own sake. A constitution lets the CEO make consistent decisions when the owner is not micromanaging the moment.
When a render fails, the constitution says: fix the workflow, do not hand-patch the output. When a cover image is needed, it says: use the channel design language, not a fresh taste judgment. When a blog post publishes, it says: verify the public URL, archive the source, and ingest the final text into the content database.
The constitution turns judgment into law.
The workflow spine: from idea to public asset
Wiki4What has two related production lines.
The first is the full video pipeline: script, fact-check, polish, structure, scene production, rendering, merge, captions, YouTube publishing, Ghost companion article, archive, and reflection.
The second is the standalone Ghost blog pipeline: research or write an English essay, create a feature image, publish to Ghost, verify the public page, archive the canonical source, and ingest it into the content database.
The important design choice is that the second line does not pretend to be the first. A standalone blog post does not need video structure, scene rendering, audio, captions, or a build directory for clips. It has its own lifecycle.
That is what a workflow spine is for: it prevents a small task from dragging the whole factory behind it.
For a standalone Ghost article, the spine now looks like this:
- Search the content database for overlap.
- Write the English source.
- Assign slugs for both English and future Chinese mirror pages.
- Generate a deterministic cover brief from the channel design language.
- Use Codex-native image generation for the still image.
- Normalize the cover to a 16:9 Ghost feature image.
- Dry-run the Ghost upsert.
- Publish after approval.
- Verify the public page.
- Archive the source, cover, brief, and metadata.
- Ingest the final content into SQLite and ChromaDB.
Notice the shape: the main agent does not “remember” the process. The workflow document does.
Roles: a small company with named jobs
The Wiki4What workflow uses roles because responsibility must be local.
If every agent is “the assistant,” no one owns anything. A script error is everyone’s problem. A broken image prompt is everyone’s problem. A stale database entry is everyone’s problem. That is how workflows become fog.
Roles cut the fog.
The main roles look like a small media company:
| Role | Responsibility |
|---|---|
| CEO | Orchestrates, reviews, verifies, reports to the owner |
| Scriptwriter | Drafts the English script or essay |
| Fact-checker | Tests claims and finds unsupported assertions |
| Polisher | Makes final prose clear, natural, and publishable |
| Structure architect | Turns a video script into scenes and handoff data |
| Scene producers | Build visual segments using the right visual backend |
| Ghost blog agent | Owns Ghost posts, mirror pages, archive, and blog ingest |
| Publisher | Publishes to YouTube when a video exists |
| Subtitle producer | Creates and realigns subtitles |
| Dev maintainer | Repairs code, CLIs, docs, skills, and agent definitions |
| Codex visual studio | Produces still images and visual assets through a contract boundary |
The boundary between Claude Code and Codex matters. Claude Code is the operating CEO and internal staff runtime. Codex is the external visual studio and code collaborator. It can do things the internal staff should not do directly, especially still-image generation, but it is reached through a contract: a brief, a file path, an expected artifact, and a report back.
That distinction is not cosmetic. It prevents image generation from becoming an invisible side effect inside a writing agent. It also lets the workflow keep a clean audit trail: who asked for the image, what brief was used, where the final file landed, and which deterministic post-processing step prepared it for publication.
Skills: training manuals, not personalities
Roles are people. Skills are manuals.
A role says, “You are the Ghost blog owner.” A skill says, “Here is exactly how Ghost publishing works: which preflight to run, which command publishes a post, how to publish a mirror Page, how to verify the public URL, and how to archive the result.”
That separation keeps the system maintainable. If the Ghost publishing API changes, the Ghost publishing skill and CLI can be updated once. The sub-agent does not need a rewritten personality. If cover design rules change, the cover brief command changes, and every future article inherits the correction.
In Wiki4What, several skills act like shared manuals:
- Ghost publishing for Post and Page upserts.
- Codex-native image policy for still images.
- R2 storage and rendering for video assets.
- Smart captions for subtitle alignment.
- Topic research for discovering new ideas.
- Design language rules for covers, templates, and UI surfaces.
The key discipline is that skills point to executable tools. A skill should not only describe an ideal. It should teach the agent which command to run.
Command line tools: where determinism belongs
The bottom layer of the company is not glamorous. It is Python, shell commands, validators, API clients, and small CLIs.
This is where serious workflows win.
If a task is repeatable, it should not stay in the model’s imagination. It should become a command:
- Check Ghost credentials.
- Generate a cover design brief.
- Normalize a cover image to 1280x720.
- Publish or update a Ghost post by slug.
- Verify that a public URL contains the expected title and image.
- Archive a blog source into the canonical folder.
- Ingest a final article into the content database.
- Search the vector database before writing.
The model is excellent at judgment, synthesis, and language. It is not the right place to hold file naming rules, retry logic, database schemas, image dimensions, or idempotency checks.
The practical rule is simple:
If the same decision will be made the same way twice, make it a CLI.
That is how a workflow becomes cheaper over time.
The archive: memory as infrastructure
A public content workflow needs more than published URLs. It needs a local memory of what was actually made.
For Wiki4What, every standalone Ghost blog article gets a content archive folder:
content_archive/ghost/<slug>/
├── source_en.md
├── source_zh.md
├── cover.jpg
├── cover_brief.json
└── publish.json
The archive is intentionally boring. That is its virtue. It gives the system a local canonical source for the English article, the optional Chinese mirror, the final cover, the cover design brief, and the Ghost metadata.
Then the database layer indexes it. SQLite stores exact metadata: content ID, title, slug, language, Ghost ID, URL, status, source path, cover path, tags, excerpt, and mirror relationship. ChromaDB stores the text chunks for semantic search.
The default search scope is canonical English content. Chinese mirror pages can be indexed, but they are marked as mirrors and excluded unless explicitly requested. That protects the editorial workflow: the English article remains the primary asset, while translations stay available for readers who want them.
This is the difference between “we published a post” and “the company learned what it published.”
Handoffs: pass handles, not payloads
A subtle but crucial rule in the Wiki4What workflow is that handoffs pass handles, not huge payloads.
Instead of pasting the entire article, the CEO passes a path. Instead of pasting every image requirement, it passes the cover brief file. Instead of asking a worker to remember the whole production history, it points to the archive or the build directory.
That keeps context windows small and responsibility clear. The worker reads the files it owns. The CEO verifies outputs. The database records final state.
This mirrors how good software systems work. Services pass IDs, not entire databases. Humans pass tickets, not oral histories. Agent workflows should do the same.
The production principle: intelligence designs, machines execute
The public lesson from Wiki4What is not that every creator needs the same tools. It is that every serious AI workflow eventually faces the same design question:
Where should intelligence live?
My answer is: put intelligence in system design, judgment, research, prose, and repair. Put deterministic execution in tools. Put memory in files and databases. Put subjective approval with the human owner. Put visual generation behind an explicit contract. Put recurring procedures into skills.
This is why the best model in the system should not be burning tokens on every mechanical step. It should be improving the company.
The company then runs cheaper, faster, and more reliably each time.
What a good workflow should contain
If you are designing your own agent-run workflow, start with this checklist:
- A constitution that states mission, priorities, red lines, and escalation rules.
- A workflow spine that names every step, output, and owner.
- A role registry that separates CEO, internal staff, external partners, and maintainers.
- Skills that act as reusable training manuals for capabilities.
- Command line tools for deterministic steps.
- A design language for visual artifacts.
- An archive standard for final sources and metadata.
- A vector database for search, deduplication, and reuse.
- Verification commands that check public reality, not agent self-report.
- A reflection loop that turns every failure into a system upgrade.
The visible output may be a video, an essay, a cover image, or a blog post. But the deeper product is the workflow company itself.
Once that company exists, the next piece of content is not a heroic act. It is an operation.
Watch more first-principles field guides on Wiki4What, or read the essays at blog.wiki4what.com.