Start, Reflect, Finalize: The Native Lifecycle of an Agent Workflow
A practical guide to the native open-and-close loop for agent workflows: start from documents, finalize with learning, and periodically turn repeated work into tools.
Chinese version: 中文版
Most AI work still begins the same way: the user explains the task, the model starts thinking aloud, and everyone hopes the right context is still somewhere in the conversation.
That may be acceptable for a one-off answer. It is not acceptable for a serious workflow.
An agent-run project is not a single prompt. It is a small operating system: laws, roles, tools, memory, archives, credentials rules, public-output rules, and handoff documents. If the agent wakes up cold and immediately starts giving opinions, it is acting like a consultant who skipped the briefing. If it finishes the task and simply disappears, it is acting like someone who pulled the power cable instead of shutting the machine down.
The third layer of the Workflow Design Bible is therefore not another production trick. It is a lifecycle protocol.
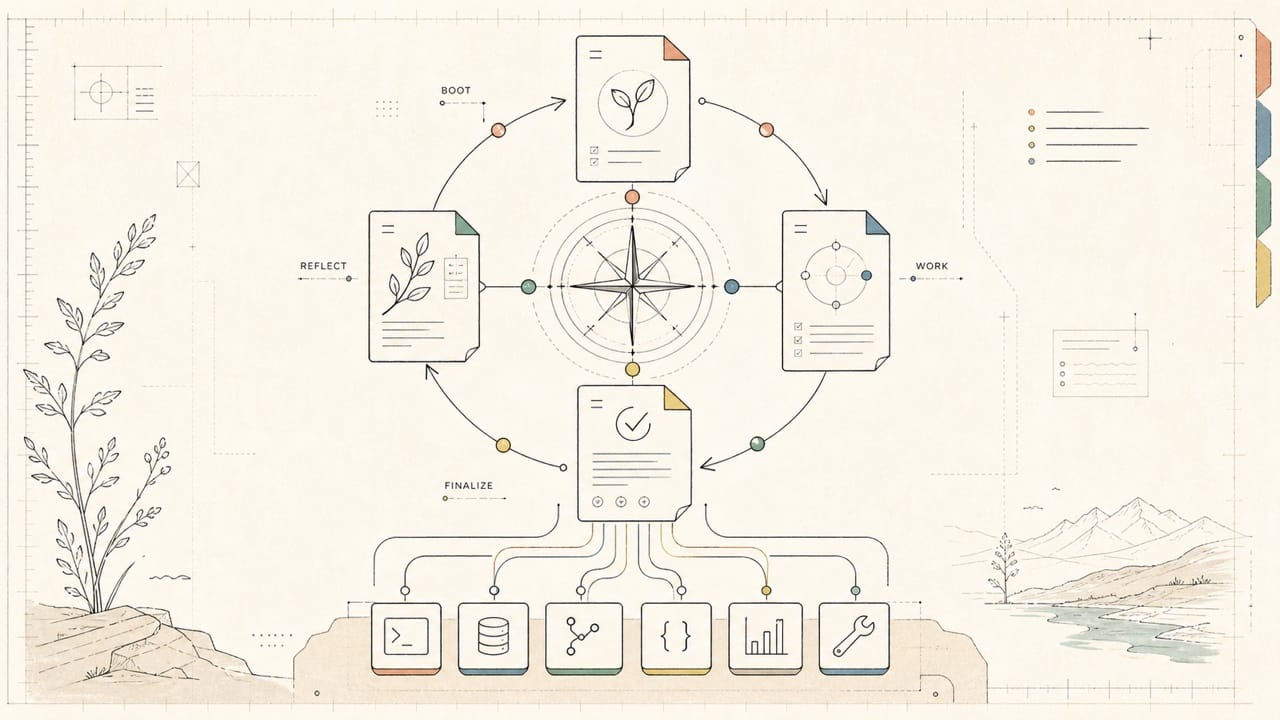
In my own workflows, four skills make that lifecycle explicit:
| Skill | Job |
|---|---|
/start-session |
Boot the project from its real documents before doing new work |
/finalize |
Close the current session by capturing lessons and fixing small defects immediately |
/self-reflection |
Audit the architecture of the whole workflow |
/self-reflection-cli |
Find deterministic work that should be demoted into code or a command |
Together, they form the native open and close cycle for an agent-run company.
Why workflows need an opening ritual
The dangerous moment in an AI workflow is not always the failure. Often, it is the first confident paragraph.
The model wakes up inside a repository, sees a few files, remembers fragments from earlier context, and starts forming a plan. The plan may sound reasonable. It may even be mostly right. But “mostly right” is how workflow drift begins.
Maybe NEXT_SESSION.md says the next action is to publish a standalone blog post, while the model assumes it should keep working on video rendering. Maybe AGENTS.md says the project has changed roles, but the model remembers the old division of labor. Maybe a tool was upgraded yesterday, but the agent reaches for the old command because it is in the conversation history.
This is why a real project needs /start-session.
The purpose of /start-session is simple: before the agent has opinions, it should load the company.
It reads the project router, then the boot documents: CONSTITUTION.md, IDENTITY.md, SOUL.md, WORKFLOW.md, ROLES.md, MEMORY.md, and especially NEXT_SESSION.md. It checks reports. If a read-only doctor exists, it can run it. Then it gives the owner a compact brief: who it is, what project this is, what state the company is in, what is blocked, and what the first concrete action should be.
That sounds mundane. It is actually one of the most important design moves in the whole system.
Without a boot protocol, context is a rumor. With one, context becomes infrastructure.
Start with documents, not thoughts
The point is not to make the agent ceremonially read files. The point is to reverse the default order of cognition.
The wrong order is:
- Think from memory.
- Guess the project state.
- Look for files that support the guess.
- Start work.
The right order is:
- Load the project law.
- Load the handoff.
- Compare the handoff against reality.
- Then decide what to do.
This matters because AI is optimized to continue. It wants to be helpful right now. It wants to produce the next useful move. That impulse is valuable during execution, but dangerous during boot. At startup, the first job is not creativity. It is orientation.
The best human teams already know this. A pilot does not invent a preflight checklist from memory. A surgeon does not walk into the operating room and improvise patient identity. A good engineer does not deploy from a half-remembered branch name.
The agent equivalent is /start-session: read the named documents, respect the handoff, and only then begin.
Why workflows need a soft shutdown
If /start-session is the clean boot, /finalize is the soft shutdown.
A lot of AI work ends badly even when the task succeeds. The code is patched. The article is published. The image is generated. The bug is fixed. Then the session closes, and the most valuable part of the work evaporates: the friction.
What went wrong? Which command was awkward? Which instruction was missing? Which step had to be repeated? Which credential rule almost caused trouble? Which public verification step caught a false success? Which part of the workflow still relied on the model remembering a fragile sequence?
During the task, the agent is focused on finishing. That is correct. But after finishing, the agent should change modes. It should become a maintainer of the workflow itself.
That is what /finalize does.
It reviews the real session that just happened: bugs, detours, repeated labor, missing docs, unstable functions, tool failures, credential risks, and sensitive-information risks. Then it asks the most important question in workflow design:
What did this session teach us that should not have to be learned again?
If the answer is small and safe, /finalize should not merely write a plan. It should fix it immediately: update the relevant documentation, adjust the skill, improve the command, add the missing note, and commit according to the project’s rules. If the answer is large or risky, it records the root cause and asks for approval.
This is the difference between task completion and organizational learning.
Finalize is not a status report
The easiest way to misunderstand /finalize is to treat it as a summary.
“Today we did X, Y, and Z. Everything is complete.”
That is not enough.
A summary records what happened. A finalize pass improves what will happen next time.
The skill is intentionally biased toward root cause. If the model had to run the same command three times, the question is not “what was the third command?” The question is why the first two attempts were possible. Was the documentation outdated? Was the CLI error message unclear? Was the expected file path not written anywhere? Was the command using the wrong Python environment? Was the decision still living in the model when it should have lived in code?
This is why I call it a soft shutdown. When you shut down a computer properly, it flushes pending writes, closes open handles, and leaves the disk in a recoverable state. /finalize does the same thing for a working session.
It flushes the tacit learning.
The deeper audit: self-reflection
/finalize looks at the session that just happened. /self-reflection looks at the architecture.
That distinction matters.
A session-level problem might be “the agent forgot to update NEXT_SESSION.md.” An architecture-level problem is “the workflow has no reliable lifecycle closure, so handoff drift is inevitable.”
The /self-reflection skill is a periodic architecture audit for a Workflow Design Bible project. It asks whether the company is still well designed:
- Is the CEO spending judgment on orchestration, or doing manual labor?
- Are roles and capabilities split cleanly?
- Are fan-out points documented and actually used?
- Is the four-layer system still intact: router, named documents, skills and roles, tools?
- Is
AGENTS.mdstill thin, or has it become a junk drawer? - Are global skills and local project skills separated cleanly?
- Does the lifecycle really close?
- Does a doctor check the document claims against reality?
- Are identity, memory, and soul useful, or bloated?
- Are credentials and sensitive information kept out of prompts, logs, and commits?
The output is not a patch. It is a REFINE & UPGRADE plan. The skill deliberately stops and asks for approval before making changes.
That restraint is important. Architecture changes affect the whole company. They should be proposed with evidence, root cause, affected files, risk, and verification. The model can discover the opportunity, but the owner should approve the direction.
The narrower audit: self-reflection-cli
The most useful recurring question in my workflows is blunt:
What is the model still doing live that should be a command?
That is the job of /self-reflection-cli.
It is not a general philosophical audit. It is a downleveling audit. It looks for work that is repetitive, deterministic, error-prone when improvised, or sensitive. The more signals a step triggers, the more urgently it should move downward into a stable function, script, CLI, or MCP wrapper.
Examples are everywhere:
- calculating publish slots across time zones;
- normalizing a Ghost cover to 1280 by 720 under a size limit;
- checking whether a public page contains the expected title and image;
- archiving a final blog source into a canonical folder;
- ingesting content into SQLite and ChromaDB;
- validating that a build directory contains every required image;
- checking whether a workflow document claims a role or skill that no longer exists.
None of these should depend on an agent being careful in the moment. They should be commands with inputs, outputs, dry-run modes, idempotency behavior, and clear error classes.
/self-reflection-cli preserves the right division of labor:
- Codex keeps deciding what matters, what tradeoff to make, and which improvement has leverage.
- Code performs the mechanical step the same way every time.
That is how workflows become cheaper and safer as they age. Intelligence migrates downward.
The lifecycle loop
These four skills create a loop:
/start-session
-> load the company
-> do the work
-> /finalize
-> capture session lessons
-> repair small defects
-> /self-reflection
-> audit the architecture
-> /self-reflection-cli
-> demote repeatable execution into tools
-> next /start-session starts from a better company
Not every session needs every audit. But every serious workflow needs the loop available.
Daily work should at least start cleanly and close cleanly. A heavy session should finalize. A recurring friction pattern should trigger self-reflection. Before weekly quota resets, if there is still high-end model budget left, spend it on architecture and downleveling instead of more mechanical execution.
That is a better use of expensive intelligence.
Hallucination is not only a factual problem
People usually talk about hallucination as a content problem: the model invents a source, a date, a claim, a quote.
In workflows, hallucination also appears as operational confidence.
The model may invent the current state of the project. It may assume a file exists. It may remember an old command. It may claim a public page is updated because the API call seemed successful. It may “know” the next step because that was the next step last time.
The cure is not to tell the model to be more careful. Care is not an architecture.
The cure is to make the workflow reality loadable, checkable, and closable:
- load project state from named documents;
- pass file paths instead of pasted payloads;
- dry-run external changes before live execution;
- verify public reality after publishing;
- archive final sources;
- ingest memory after completion;
- finalize the session;
- periodically audit what should become code.
This is how a workflow compensates for the model’s nature. The model is brilliant, but it is not a database, not a scheduler, not a credential vault, not a release manager, and not a filesystem manifest. Let it judge. Let the system remember.
A mature workflow learns on purpose
The real promise of agent workflows is not that they can complete a task once. Humans have always been able to complete tasks once.
The promise is that the system can improve after every task.
A mature workflow should notice its own pain. It should turn repeated pain into tools. It should turn ambiguous decisions into documented policy. It should turn public-output mistakes into verification gates. It should turn missing handoffs into lifecycle rules. It should turn useful discoveries into memory, and settled memory into docs or code.
That is why the open and close skills matter so much. They give the workflow a metabolism.
/start-session lets the company wake up as itself.
/finalize lets the company digest what just happened.
/self-reflection lets the company redesign its structure.
/self-reflection-cli lets the company move labor from fragile intelligence into stable machinery.
This is the native lifecycle of an agent-run workflow: boot from truth, work with judgment, close with learning, and periodically redesign the machine that does the work.
Once that loop exists, a workflow is no longer just a clever sequence of prompts.
It becomes a company that remembers how to get better.
The Workflow Design Bible is open source under MIT: github.com/preangelleo/workflow-design-bible.
Watch more first-principles field guides on Wiki4What, or read the essays at blog.wiki4what.com.