The Design Philosophy of Workflow Designer
The smartest AI model should not do every step of the work. It should design the workflow company that cheaper models and deterministic code can run again and again.
Chinese version: 中文版
Why I built an open-source “constitution generator” for agent-run projects — and what the most expensive model in the world should actually be used for.
The $200 question
When Anthropic’s newest frontier model became available again, everyone asked me the same thing: what should we use it for? It is brilliant, and it is expensive. I’m on the top-tier $200/month 20x plan, and one hour of work with it burned through 10% of my entire weekly quota. You cannot afford to put a model like this on every step of your pipeline — and you shouldn’t.
So what is it for?
After giving it two hours of carefully chosen work, the answer crystallized for me:
The most intelligent model should not be a worker in your workflow. It should be the designer of your workflow.
Use it as a workflow refiner. Let it design, audit, and upgrade the system that all the cheaper models and deterministic code will then run a thousand times. Design is a one-time cost with compounding returns; execution is a recurring cost that must be driven down relentlessly. Spend your smartest tokens where the leverage is.
That principle — and everything that follows from it — is why I built the Workflow Design Bible, an open-source meta-prompt that turns any project into a fully structured, agent-run company in a single sitting. This post is about the design philosophy behind it.
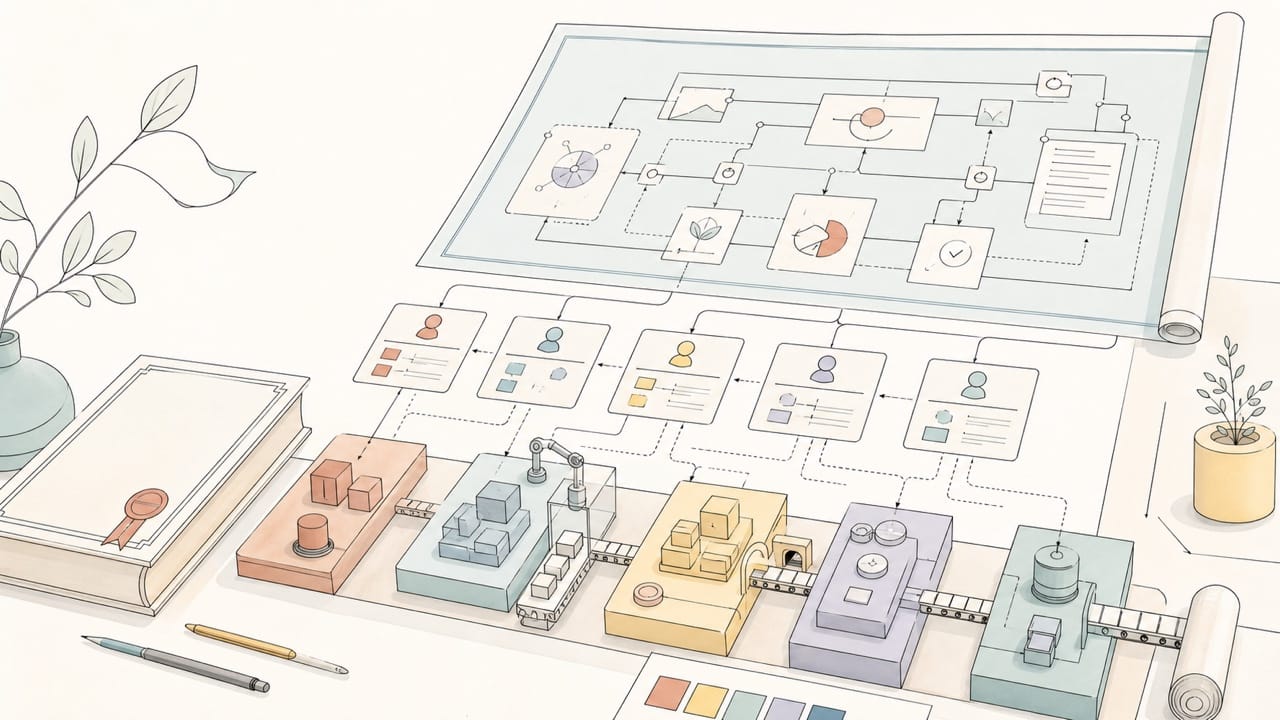
A workflow is a company
The core mental model is simple: an autonomous workflow is a company, and the main agent is its CEO.
The CEO doesn’t do manual labor. Its job is to orchestrate, supervise, review, and talk to the owner (you — the chairman). Every fixed, repeatable step of the work is delegated to an employee. Once you see it this way, all the classic questions of organizational design come rushing in, and they all need answers in writing:
- What are the company’s laws? (Constitution)
- What exactly does the company produce, step by step? (Workflow)
- Who works here, and what is each person responsible for? (Roles)
- What training manuals do employees share? (Skills)
- What machines does the factory floor run on? (Functions & CLI tools)
- How do shifts hand off to each other? (Handover documents)
A workflow that only exists in the model’s “head” — improvised fresh in every session — is not a company. It’s a talented freelancer with amnesia. The whole point of workflow design is to move knowledge out of the model’s working memory and into a document system that any competent agent can boot from.
The constitution: stable law, not daily policy
Every generated project starts with a CONSTITUTION.md. This is deliberately named. A constitution is the document that almost never changes: the mission, the priority-ordered non-negotiables (“account safety > quality > quantity > speed”), the red lines that can void the entire project, and the Don’ts — split into Forbidden and Discouraged.
Everything else in the system is allowed to evolve session by session. The constitution is the fixed point that evolution orbits around. When the CEO faces an ambiguous judgment call at 3 a.m. with no human awake, the constitution is what it falls back on.
The workflow spine: step zero to final step
Next to the law sits WORKFLOW.md: the pipeline spine, described step by step from step zero to the final step. Each step declares three things — what it does, what it outputs, and which role leads it.
Two details matter more than people expect:
1. The baton between steps is a handle, not a payload. Steps pass a task_id and the smallest index needed — never long text pasted through chat. Each worker reads its own inputs from disk. This keeps context windows lean and steps genuinely decoupled.
2. Concurrency is declared at the seams, not on the workers. Some steps are independent and should fan out simultaneously (compile, cover art, and copywriting can all start the moment the manuscript is ready). Some steps are homogeneous batches — sixty scene images, fifty in flight at once. And some roles exist purely for clarity of responsibility and will always run single-threaded. The workflow document marks exactly which is which, at the fan-out points. Parallelism is an architectural property of the pipeline, not an improvisation of the moment.
Roles: internal employees vs. external contractors
Here is a distinction I’ve come to consider essential, and one most agent frameworks ignore: not everyone who works for your company is your employee.
In my own pipelines, Claude Code’s sub-agents are the internal staff. The CEO dispatches them natively — same runtime, same tool conventions, results returned in-process. But Codex is an external contract partner. It has capabilities my internal staff doesn’t (it does all my illustration work), and I cannot dispatch it the way I dispatch an employee. Communication runs through a formal protocol: a file-based bridge, a written contract describing the deliverables, a notification to wake it up, and a written report coming back.
Internal employees and external contractors differ in every dimension that matters:
| Internal sub-agent | External contract partner | |
|---|---|---|
| Invocation | Native dispatch, in-process | Bridge protocol, asynchronous |
| Contract | System prompt + task brief | Formal written handoff contract |
| Trust model | Shares the company’s context | Sees only what the contract states |
| Accountability | CEO reviews output directly | Must file a completion report |
Your ROLES.md has to draw this boundary explicitly. Each internal role gets a system prompt defining who it is, which workflow step it owns, and — critically — which skills it should mainly use. A sub-agent can see dozens of skills in the environment; seeing is not license to use. Each role’s charter narrows its toolbox on purpose, the way a job description keeps the accountant out of the paint shop.
Skills: shared training manuals
Skills sit one layer below roles, and the relationship is many-to-many: different sub-agents can share the same skill, and one sub-agent may use several. A skill is a training manual for one capability — how to publish to the blog, how to run the image-generation contract, how to do the quality-gate check — including which underlying tools it is built from.
This layering is what keeps the system from collapsing into one giant prompt. The CEO knows who to dispatch; the role knows which manuals apply; the manual knows how the capability works; and below all of that sits the machinery itself.
The ground floor: Python functions
At the very bottom of the stack — beneath CEO, beneath roles, beneath skills — live the plain functions. In my projects they’re Python. They are the most fundamental elements of the whole architecture, and the most underrated.
Here is the macro-level division of labor that everything else serves:
LLMs are for creation and decision. Code is for execution.
A large language model is the best tool humanity has ever built for the two things that used to require a human: creating (writing the script, designing the scene, crafting the image prompt) and deciding (what to do when a step fails, whether quality passes the gate, how to handle the ambiguous case). Everything else — rendering, compiling, uploading, retrying, file management, format conversion — should be executed by deterministic functions: exactly as coded, fast, cheap, and identical every time.
Even the composition of small functions shouldn’t be improvised by the model each run. Higher-order pipeline functions chain the atomic modules together deterministically. The model’s involvement shrinks to the narrow, high-value slice: create the content, make the judgment calls at the checkpoints, decide what to do when something breaks. The moment a decision is made, code takes over.
This gives the system a beautiful long-term dynamic: every recurring decision is a candidate for demotion into a function. If the CEO notices it has made the same judgment call the same way five sessions in a row, that’s not a decision anymore — it’s a rule, and rules belong in code. My projects run a periodic self-audit dedicated to exactly this: find what the model is still doing “live” that should be frozen into a deterministic CLI. Over time the workflow gets cheaper, faster, and more reliable by design, because intelligence keeps migrating downward into infrastructure.
This is also the real answer to the cost question from the top of this post. The expensive model designs the company. The mid-tier models staff it. The functions run it. Each layer of the hierarchy is cheaper and more deterministic than the one above it, and the architecture’s job is to push every possible gram of work down the stack.
The document system is the company’s operating system
Pull all of this together and you get a fixed, named document set that every project shares:
CONSTITUTION.md— the law: principles, priorities, red lines, Don’ts.WORKFLOW.md— the spine: every step, its output, its lead, the fan-out points.ROLES.md— the org chart: internal roster, external partners, skill assignments.- Playbooks — topic-specific SOPs: quality gates, compliance, pricing.
NEXT_SESSION.md— the shift handover, rewritten in full at every close.IDENTITY.md/SOUL.md— who the agent is, and the character it grows over time.STRUCTURE.json— a machine-readable manifest of everything the docs claim exists.
The root instruction file (CLAUDE.md, AGENTS.md, whatever your runtime reads) is deliberately thin — just a boot router pointing to these documents. Anything written in the root file is carried as overhead on every single turn; anything in a named document is loaded once per session. Same knowledge, a fraction of the cost.
And because documents drift from reality, every project ships a deterministic doctor command that checks the manifest against the actual filesystem and fails loudly on any mismatch. Constitution-as-code: the claims must equal the reality, verified by a machine, not by good intentions.
Finally, every session runs a lifecycle — /start-session boots from the documents, work happens, /finalize-session reflects, updates the living docs, rewrites the handover, and runs the doctor. No finalize, no closed loop. Reflection isn’t a nice-to-have at the end; it is the mechanism by which the company learns.
Why a Bible
Once I had rebuilt this same structure for a content channel, an ebook press, and a game studio, the pattern was obvious — and patterns this stable deserve to be generated, not handcrafted.
The Workflow Design Bible is that generator. It’s a single reusable meta-prompt: it interviews you about your project — mission, red lines, brand, pipeline steps, roles, credentials — and then scaffolds the entire company in one pass: the constitution, the workflow spine, the org chart, the document system, the session lifecycle, the manifest. It writes no business code and deploys nothing. It does the one thing the smartest model is actually for: it designs the company, so that everything cheaper than it can run the company.
That’s the design philosophy. Roles clearly divided, laws clearly written, execution pushed down into code, intelligence reserved for creation and judgment — and the whole thing born, fully documented, on day one.
The Workflow Design Bible is open source under MIT: github.com/preangelleo/workflow-design-bible.
Watch more first-principles field guides on Wiki4What, or read the essays at blog.wiki4what.com.